

Foto Credit: Morris Mac Matzen
Eugen L. Gross
„Mein Wunsch für die Zukunft von Künstlicher Intelligenz ist, dass alle Menschen verstehen, dass es keine Science-Fiction ist, sondern ein Schweizer Taschenmesser, das jeder nutzen sollte.“
Eugen Gross hat langjährige Erfahrung in vielen Bereichen der TV- und Bewegtbildproduktion sowohl von der kreativen als auch der technischen Seite. Er hat eine Ausbildung zum Kameraassistenten in Wien absolviert, als Kameramann hauptsächlich für Show und Unterhaltungsformate gearbeitet, war SNG Operator und Ü-Wagenleiter, hat selbst produziert und Regie geführt.
Aufgrund der Veränderung des Marktes und der Digitalisierung der Medien sah er die Notwendigkeit einer beruflichen Veränderung. Neben vielen kleineren Workshops hat er sich in Köln zum Producer fortgebildet und anschließend an der Hamburg Media School den Zertifikatslehrgang „Executive MBA in Media Management“ absolviert. Seine fundierte Berufserfahrung konnte er dort durch das praxisnahe Studium erweitern. Aus der Masterarbeit ist aiconix entstanden.
Gunnar Brune/AI.Hamburg: Herr Gross, Sie waren Kameramann und jetzt setzen Sie Künstliche Intelligenz für die Analyse von Videos ein. Was machen Sie und wie kam es dazu?
Eugen L. Gross: Ich bin als Kameramann komischerweise immer an Daten interessiert gewesen. Ich glaube, ich war der Einzige, der eine Pivottabelle gemacht hat, um auszuwerten, wie viele Tage ich gearbeitet habe, wie viele Reisetage ich hatte usw. Das hat mich immer interessiert. Ich war immer technisch affin, zeitweise war ich Ü-Wagenleiter und sogar ein bisschen Satellitentechniker. Ich komme nicht vom „Film“. Das habe ich zwar ganz früher gemacht, genau genommen komme ich vom Fernsehen. Ich bin der klassische Fernseh-Fuzzi. Meine Welt, das war die Show klassische Unterhaltung. 20:15 Uhr, Vorhang auf für die Red Hot Chili Peppers, auch Thomas Gottschalk und Anne Will.
Gunnar Brune/AI.Hamburg: Sie haben vor allem Live-TV gemacht?
Eugen L. Gross: Ja, ich habe natürlich auch Dokus gemacht. Ich habe zum Beispiel eine Produktionsfirma für eine Langzeit-Doku in Kiel gehabt. Aber mein Daily Business war über viele, viele Jahre die Unterhaltung. Ich habe 80 Konzerte gemacht von Tokio Hotel bis Helene Fischer, von Marianne und Michael bis zu den New Yorker Philharmonikern. Ich habe alle Talks gemacht von Harald Schmidt bis Anne Will und Beckmann. Ich habe auch einen Berufsverband für Fernseh-Kameraleute mitgegründet.
Gunnar Brune/AI Hamburg: Und jetzt arbeiten Sie nicht mehr mit der Kamera, sondern mit Künstlicher Intelligenz. Wie sind Sie dazu gekommen?
Durch meinen MBA in Media Management kam ich auf die Frage, wie man Daten besser nutzen kann. Ich bin der Meinung, Daten werden aktuell zu viel für den Vertrieb genutzt und zu wenig, um besseren Content und bessere Produkte zu entwickeln. Man muss einfach alle Faktoren zusammenbringen, und das geht nur mit Künstlicher Intelligenz. Und mit dieser Idee habe ich aiconix gegründet.
Gunnar Brune/AI Hamburg: Was ist Ihr spannendstes Projekt gerade?
Eugen L. Gross: Das Spannendste ist immer das Aktuellste. Spracherkennung, also Speech-to-Text ist im Moment das, worum sich fast alles dreht. Vieles beginnt mit Speech-to-Text. Vertrieblich: Die Kunden beginnen mit Speech-to-Text. Auch die Inhalte eines Videos werden heute anhand des Textes erkannt, dabei ist egal, wie das Bild aussieht. So ist das heute, dazu kann ich später noch mehr erzählen. Gerade bei Kurzformaten transportiert die Sprache die Informationen.
Wenn ich Sprache in Informationen bzw. Text umwandeln kann, dann kann ich sie semantisch analysieren und ich kann Topics extrahieren. Dafür benötigt man Speech-to-Text und wir haben da in alle Richtungen Lösungen. Wir haben ein Frontend und bieten eine API, also eine Schnittstelle an. Außerdem haben wir einen Slackbot. Und, hier sind wir Vorreiter, wir machen das auch live. Wir machen das schon für den Hessischen Landtag. Wir bewerben uns gerade für ein Projekt im Deutschen Bundestag. Wir haben Anfragen von Staatsanwaltschaften, der Polizei, oder der Bundespressekonferenz. Bei letzterer geht es zum Beispiel um Live-Untertitel. Damit ist Speech-to-Text für uns auch betriebswirtschaftlich gerade besonders wichtig.
Wir sind dabei Cloud-agnostisch und deshalb breit aufgestellt. Wir sind im Oracle-Startup-Programm, sind gerade eine Partnerschaft mit Microsoft eingegangen, wir nutzen parallel Amazon, Google, viele kleine Provider und sind für alles offen.
Gunnar Brune/AI.Hamburg: Sie nehmen also den Sound auf, erfassen die Texte und dann laufen sehr, sehr schnell semantische Analysen?
Eugen L. Gross: Fast, es läuft sehr, sehr schnell Speech-to-Text. Wenn du Semantik haben möchtest, ist das ein extra Call. Du musst erstmal den Text bekommen und den schickst du nochmals zu einem anderen Provider und kannst über den dann die Topics extrahieren. Dabei ist extrem interessant, bei längeren Videos oder Podcasts Inhaltsverzeichnisse mit Zeitangabe anzulegen. Mich wundert, dass das vor uns meines Wissens noch keiner gemacht hat! Ein Podcast ist ein gutes Anwendungsbeispiel. Bei einem langen Podcast, der 60 Minuten dauert, möchte ich doch nicht die 60 Minuten durchhören, um den einen Punkt zu finden, der mich interessiert. Ich möchte gerne wissen, dass es in den ersten zehn Minuten ein Intro gibt, in den zweiten zehn Minuten geht es – zum Beispiel – um eine Berufsbeschreibung und in den dritten zehn Minuten geht es um AI. Ich möchte mir vielleicht nur die dritten zehn Minuten mit dem Thema AI anhören. Ich möchte auch nicht alle 20 Folgen eines Podcasts anhören, wenn nur die Folge 14 mein Interesse AI betrifft. Spotify hat gerade ein großes Projekt ausgeschrieben, an dem man als Entwickler teilnehmen kann. Hier geht es um die Frage, welche Möglichkeiten es gibt, thematisch in die einzelnen Folgen hineinzugehen.
Nehmen wir an, du warst bei einem langen Webinar oder bei einer Konferenz, die acht Stunden gedauert hat. Am Ende wird ein Video zur Verfügung gestellt. Du kannst dich an einen besonders interessanten Vortrag erinnern, oder es wurde eine spannende Sache gesagt, aber du kannst nicht Control-F drücken und die Suchfunktion zu aktivieren, um auf dieses Stichwort zu springen. Du hast meistens auch keinen Überblick über die Themen. In diesen Anwendungen ist noch viel Musik drin und es beginnt alles mit Speech-to-Text.
Gunnar Brune/AI.Hamburg: Klingt super, aber wie lösen Sie die Tücke im Detail? Wie wird die Sprache erkannt?
Eugen L. Gross: Das wäre schön, aber keine Künstliche Intelligenz für Speech-to-Text kann zur Zeit Sprache im Moment des Sprechens erkennen. Manche Provider testen in den ersten sieben bis zehn Sekunden, um welche Sprache es sich handelt. Es gibt dafür noch keine andere Lösung. Du hast Geräusche angesprochen, das ist ein Riesenthema. Wenn du im Hintergrund Musik hast, kannst du sie wegfiltern. Wenn du Straßengeräusche hast, kannst du sie wegfiltern. Aber wir haben noch keine Lösung gefunden, generell die Sprache zu extrahieren, um alle Geräusche wegzufiltern. Das was der Mensch so gut kann. Als Mensch kann ich zwischen all diesen Geräuschen die Sprache erkennen. Wir haben noch kein Modell gefunden, welches dies allgemeingültig kann. Wir können das immer nur für einzelne Geräusche oder für Geräuschgruppen machen. Was funktioniert, ist die Sprache zu verbessern, um sie besser zu erkennen zu können. Die AI hat inzwischen eine gute Qualität. Wenn ein Sprecher deutlich spricht, zum Beispiel, wenn er politische Reden hält, dann ist das unser Ideal. Denn diese sind meist geübte Sprecher mit einem guten Mikrofon. Aber in dem Moment, und wir haben dazu aktuell ein paar Cases, in dem in einer Reality-TV-Sendung gesagt wird „Ey Dicker, Alter“, dann wird das ein Desaster. Auf einer Messe war die Digitalstaatsministerin Dorothee Bär bei uns zu Gast. Die fragte dann: „Kann der a’ fränkisch?“ Die Antwort war natürlich „Nein, der kann kein Fränkisch“. Ich bin Österreicher. Sobald du in den Dialekt kommst, geht die Qualität deutlich zurück. Das liegt daran, dass die deutsche Sprache keine so große Bedeutung in der Welt hat. Für die englische Sprache gibt eine deutlich größere Datenbasis, mit der trainiert werden konnte Deswegen kann Künstliche Intelligenz einen Inder oder einen Australier, die Englisch sprechen, relativ gut verstehen und erkennen. Bei der deutschen Sprache ist es so, dass die Qualität der Künstlichen Intelligenz in München oder in Wien heruntergeht, weil sie auf Hochdeutsch trainiert ist und die Dialekte ein Riesenthema sind. Dabei sind Dialekte für mich ein echtes Herzensthema. Ich habe im Kopf und als Architektur schon eine Lösung dafür, aber leider noch kein Budget, um das umzusetzen.
Aktuell ist es so, dass wir mehrere Künstliche Intelligenzen nutzen, um das Optimum für Speech-to-Text zu erzielen. Wenn diese sich bei einem Begriff nicht einig sind, welcher der Richtige ist, so wird dieser unterstrichen. Dann werden einem die verschiedenen Optionen angeboten. So muss man sich nicht um den ganzen Text kümmern, sondern nur noch um die blau markierten Wörter, bei denen die AIs unterschiedlicher Meinung waren. Im Text ist das ganz einfach zu sehen: Alles, was schwarz ist, ist eine 100 Prozent-Trefferquote. Bei Grün geht es um Groß- und Kleinschreibung, wir haben den Prozess so optimiert, dass dies als erstes geprüft wird. Bei Blau wird es interessant, weil unser eigener Algorithmus mehrere Quellen mit unterschiedlichen Ergebnissen für seine Entscheidung bewertet hat. Schwierig sind zum Beispiel Zahlen: Bei Zahlen ist es so, dass manche Provider diese Zahlen ausschreiben, andere geben Zahlen in Ziffern an. Wenn ein Text ganz viele blaue Markierungen hat, dann hat unser Algorithmus ganz stark arbeiten müssen, weil es immense Unterschiede zwischen den einzelnen Providern gab. Das bedeutet, die Künstliche Intelligenz ist ein Gerüst. Und unsere hilft als Meta-Ebene, die die höchste Wahrscheinlichkeit für Speech-to-Text zurückgeben kann. Aber ich würde jedem empfehlen, gerade wenn es um sensible Daten geht, die nicht falsch sein dürfen, noch einmal eine Endkontrolle zu machen.
Was bedeutet das praktisch? Nehmen wir ein 4-Minuten-Video. Das braucht wahrscheinlich so 20 bis 30 Minuten Arbeit, wenn man es abtippt. Um eine Untertitel-Datei zu erstellen mit einem Sekundencode benötigt man in der Regel das Zehnfache, also vierzig Minuten für das 4-Minuten-Video. Mit AI-Unterstützung kostet es nur ein paar Cent zuzüglich der Endkontrolle. Das heißt, der Workflow ist immens viel preiswerter und schneller.
Zusammengefasst: Mit unserem Speech-to-Text-Service sind wir einerseits ein Meta-Anbieter, d.h. wir haben einen Algorithmus, der die Daten anderer Anbieter optimiert, so dass die höchsten Wahrscheinlichkeiten erreicht werden. Dazu trainieren wir auch eine eigene AI, nicht als eigene Spracherkennung, sondern als Supporting-Technologie. Für den Auftrag des Landtags mussten wir für die Transkription erstmal besser sein als Google. Das geht natürlich durch unseren Meta-Algorithmus immer ganz gut. Aber es war ganz klar, wenn ein Abgeordneter auf die Bühne geht und der Parlamentspräsident diesen ankündigt „Hier ist der Abgeordnete Vranitzky“, dann muss der richtig erkannt werden, auch wenn der keinen Namen hat, der im Wörterbuch steht wie Meier oder Müller. Genau das kann Google nicht, weil deren Technologie natürlich viel breiter aufgestellt ist. Wir trainieren für die Aufgaben unserer Kunden diese speziellen Worte an. Zum Beispiel wird für eine medizinische Konferenz das medizinische Vokabular zusätzlich trainiert. Wir hatten letztens ein Thema, weil Zahlen schlecht in der Live-Transkription erkannt wurden. Dieses Problem war uns prinzipiell schon bekannt, denn wie gesagt sind Zahlen oft eine Schwäche der Modelle. Es gab in dem speziellen Fall aber absurde Fehler. Phonetisch wird manchmal eine Million mit einer Milliarde verwechselt, aber in diesem Fall wurde 38 zu 24, was eigentlich phonetisch überhaupt nichts miteinander zu tun hat. Wenn wir so eine Besonderheit entdecken, trainieren wir ganz konkret.
Gunnar Brune/AI.Hamburg: Der aktuelle Nutzen ist klar. Ich kann sogar lesen, was gesagt wird, und ich kann es sehr, möglicherweise relativ schnell bekommen, mit weniger Aufwand, auch weniger Stenografen. Wohin geht die Reise? Welchen Nutzen wird uns das in Zukunft bringen?
Eugen L. Gross: Vieles wird viel schneller gehen. Meinen letzten Film habe ich in Mexiko für Red Bull gemacht und damals habe ich zwei Tage auf das Transkript und die Übersetzung gewartet, bis ich im Schnitt weiterarbeiten konnte. Das geht mit AI jetzt schon sehr viel schneller und besser. Ich habe letztens mit einem Journalisten gesprochen, er ist Abteilungsleiter von einem Wirtschaftsmagazin. Wenn er ein Interview führt, dann nimmt er das mit dem
iPhone auf. Er verdient ganz gut. Trotzdem muss er selbst transkribieren. Da sitzt er dann 3 Stunden am Tag mit den Aufnahmen von seinen eigenen Interviews und tippt sie ab. Das muss nicht sein. Das kann AI sehr viel schneller, besser, kostengünstiger. Er sollte sich darauf konzentrieren, einen Artikel zu schreiben, denn das ist seine Kernkompetenz ist.
Gunnar Brune/AI.Hamburg: Wie kommen Sie an Ihre Algorithmen? Nutzen Sie Kataloge oder arbeiten Sie mit Mathematikern, die Ihnen Algorithmen schreiben?
Eugen L. Gross: Sowohl als auch. Der erste Schritt bei unserer Plattform war tatsächlich, die AI-Angebote von Google, Amazon und Microsoft anzusehen. Was können die? Und wie können wir als Metaebene einen Benefit generieren, in dem wir kuratieren? Welcher Algorithmus ist für den Use Case der Beste?
Gunnar Brune/AI.Hamburg: Verstehen Sie mich nicht falsch. Sie sind Kameramann, wie konnten Sie das beurteilen?
Eugen L. Gross: (lacht) Na ja, ganz einfach, indem du eine Sprachaufnahme in die Maschine wirfst und parallel ein Transkript manuell angefertigt hast. Nehmen wir an, Microsoft machte 60 Fehler, Amazon 20 Fehler und Google vielleicht nur zehn Fehler, dann wussten wir, dass Google die besten Ergebnisse hat.
Gunnar Brune/AI.Hamburg: Sie haben es also einfach ausprobiert? Sie haben nicht die mathematischen Formeln analysiert, sondern gesagt, wir probieren das einfach aus, und was besser ist, ist besser?
Eugen L. Gross: Genau. Wir haben tatsächlich von der Sprache ein manuelles Transkript angefertigt und dieses manuelle Transkript gegenüber den Transkripten, der AI gebenchmarkt, unter idealen Verhältnissen. Und wir haben festgestellt: Das Ergebnis ist in jeder Sprache anders. Der eine Anbieter ist in Deutsch besser, der andere ist besser in Englisch oder Russisch. Wenn jemand Russisch transkribieren möchte und uns auswählt, dann kriegt er einen anderen Provider und genau das ist unser Versprechen. Du kannst bei uns den billigsten Provider nutzen, der dann aber nur 80 Prozent der Accuracy hat, die der Beste liefert. Wenn dir das reicht, weil es um den Schnitt eines Langformats einer Dokumentation geht, also um grob zu verstehen, worum es geht, dann ist das schon genug. Aber; wenn du eine Nachrichtenagentur bist, unter Druck arbeitest und Untertitel brauchst, dann wird eine bessere Qualität verlangt. Dann kriegst du bei uns auch die besten Ergebnisse. Das ist unser Versprechen.
Gunnar Brune/AI.Hamburg: Ihr Modell ist also, Künstliche Intelligenz für die Aufgaben Ihrer Kunden zu kuratieren. Man kann einfach nur den einen preiswerten Algorithmus laufen lassen. Oder man kann die 10 Besten nutzen und die Meta-Auswertung dazu nutzen?
Eugen L. Gross: Richtig. Das ist aber auch nur der Anfang für uns. Wir haben den Algorithmus gebaut, den ich vorhin beschrieben habe, der aus den verschiedenen Quellen, die Daten vergleicht und die Antwort mit der höchsten Wahrscheinlichkeit anbietet. Zu Beginn war es ein smartes Modell, weil wir Kunden ersparen, verschiedene Implementierungen von Apps machen zu müssen, denn wir haben sie alle schon eingebunden. Aber das Ziel war natürlich sehr schnell, dass wir nicht nur Daten von anderen verkaufen, sondern eigene Modelle anbieten. Und die haben wir sofort angefangen zu trainieren. Wir haben eine eigene Gesichtserkennung entworfen. Wir haben Einstellungsgrößen von Aufnahmen in ein eigenes Modell gebaut. Das war für mich als Kameramann auch für die Vision, die wir haben, sehr wichtig. Dieses Modell erkennt, ob eine Person im Closeup oder in der amerikanischen Einstellung. Ist sie „head to toe“? Wie viele Personen stehen im Bild? Das ist ein eigenes Modell und eine spannende Anwendung für die Zukunft.
Gunnar Brune/AI.Hamburg: Wir sind also bei der Bilderkennung angelangt. Vorher haben wir viel über Sprache gesprochen, wie weit ist die Analyse der Bilder mit AI?
Eugen L. Gross: Ich habe diesen Case, da ist eine Werbeagentur an uns herangetreten, um zu eruieren, warum manche Social-Media-Postings für einen Kunden, einen Auto-Hersteller gut laufen und andere nicht gut laufen. Wir sind von der Arbeitshypothese ausgegangen, dass die Perspektive, in der ein Auto fotografiert wurde und die Farben, mit denen es dargestellt wurde, einen Einfluss auf den Erfolg der Postings bei der Zielgruppe haben. Wir unterscheiden hier zum Beispiel zwischen braunen, wärmeren Farben in einem ländlichen Umfeld oder stahlblauen Farben im städtischen Umfeld mit Hochhäusern. Der Gedanke ist, dass man sich vielleicht als städtischer Mensch mehr für ein SUV im urbanen Umfeld interessiert oder vielleicht genau das Gegenteil, weil man sich mit dem SUV in der Stadt bewegt, aber sich selbst als Landmensch versteht. Das ist mit der AI gut zu eruieren, denn es gibt dafür Anwendungsfälle und vor allem auch Provider, die Farbspektren aus Bildern extrahieren, die Fahrzeuge erkennen. Die auch erkennen können, von welcher Perspektive das Fahrzeug fotografiert wurde, also von der Seite, von vorn oder von hinten. Die identifizieren, wie viel Prozent des Bildes mit einem Fahrzeug bedeckt werden. Das ist ein Ansatz, der in Richtung visuelles Storytelling geht und dabei geht es um die Beantwortung der Frage, welche Bilder gut beim Publikum ankommen.
Der Grund, warum ich dieses Startup gegründet habe, ist genau dieser: Ich bin der Meinung, dass zu viele Daten für Marketing und Sales verwendet werden und zu wenige für die Kreativen. Daten können die Kreativen sehr gut darin unterstützen, zu verstehen, warum die Zielgruppe in der Sekunde 50 abgeschaltet hat. Was ist denn in Sekunde 50 passiert? Damit meine ich nicht die Ebene der einzelnen Person, sondern die ganze Zielgruppe. Wenn ich 20 Prozent dieser Zielgruppe verliere, dann muss ich mir doch als Kreativer ansehen, was in diesem Storytelling falsch gelaufen ist. Das ist das große, große Ziel, mit dem wir wahrscheinlich auch weltweit sehr viel mehr Potenzial haben. Und daran arbeiten wir gerade.
Wir haben hier ja mehrere Ansätze, und wir haben drei verschiedene Quellen. Die eine ist das Medium selbst – im aktuellen Fall ein Online-Kurzformat. Die zweite Quelle sind die Daten, die wir daraus extrahieren können und uns sagen: Wer spricht über welches Thema? Wie ist die Schnittfolge? Wir können natürlich auch die Farben anschauen. Wir können das Thema extrahieren. Diese Daten sind alle vorhanden, und wir können alles, was noch veränderbar ist am Schnittplatz, auch mit Daten eruieren. Man kann die Hintergrundmusik bestimmen, zumindest im Großen und Ganzen. Vielleicht auch die Personen und das Thema zusammen matchen und analysieren, ob eine Person für ein Thema für die Zielgruppe glaubwürdig ist. Als dritte Datenquelle haben wir die Zielgruppe. Dazu haben wir ein Neuro-Labor aufgebaut, in dem wir die EEG-Daten von Probanden messen. Wenn wir an den Analysedaten sehen, dass die Zielgruppe in Sekunde 50 abschaltet dann ist nicht in dieser Sekunde ein Problem aufgetaucht, sondern das Problem ist die Summe aller Informationen, die wir vorher gegeben haben. Vielleicht hätten wir den Film dramaturgisch etwas anders aufbauen müssen. Vielleicht hätten wir einfach die Szenen umsortieren sollen, hätten ein anderes Storytelling gehabt und das Publikum nicht verloren. Um zu messen, was die ausschlaggebenden Punkte sind, warum das Publikum abschaltet, muss man in den Kopf schauen. Das kann man im Moment nur mit dem EEG-Gerät. Wir haben das auf einem ganz hohen Niveau gemacht in einem Labor mit einem 40.000-Euro-Gerät. Das ist kein Spielzeug, denn wir müssen sehr viele Informationen sammeln. Wir haben anhand der Daten sehen können, wie sich die Aufmerksamkeit entwickelt. Noch können wir nicht sagen, ob ein Moment spannend ist oder nicht. Hier gibt es noch viel zu lernen.
Online-Videos haben den Vorteil, dass ich sehr schnell viele Daten zur Verfügung habe. Ich habe schnell 10.000 Leute, die alle in derselben Sekunde abgeschaltet haben. Das heißt, es geht darum, wie die Geschichte erzählt wird, es geht es um das Storytelling. Und da wollen wir hin: Wir wollen mit Künstlicher Intelligenz helfen, guten Content zu produzieren.
Gunnar Brune/AI.Hamburg: Wohin geht die Reise?
Eugen L. Gross: Mein Wunsch für die Zukunft von Künstlicher Intelligenz ist, dass alle Menschen verstehen, dass es keine Science-Fiction ist, sondern ein Schweizer Taschenmesser, das jeder nutzen sollte.
Aktuell haben wir die Information aus der Sprache und was im Bild passiert. Wir wollen uns jetzt um das Storytelling kümmern. Auch bei einem 5-minütigen Kochvideo möchte ich verstehen, ob das ein Dreiakter ist, wo das Intro ist und wo der Hauptteil. Wo ist der Plot? Beim Kochvideo ist der Plot, wenn das Gericht fertig ist. Wenn ich verstehe, wie eine Geschichte funktioniert, dann kann ich auch dem Filmemacher anhand der Daten der letzten tausend Videos, die er gemacht hat, sagen, was besser funktioniert hat und was nicht. Was besser verstanden wurde und was nicht. Damit können wir Empfehlungen geben, wie man den Film besser machen oder dramaturgisch optimieren kann, damit er nicht das Publikum verliert. Und dem Werbetreibenden kann ich sagen: Lieber Werbetreibender, bitte buche nicht die Mid-Roll bei Sekunde 30, das ist mitten im Satz, das ist mitten in der Szene. Ich kann dir sagen, wo die Wahrscheinlichkeit viel geringer ist, dass du dein Publikum verlierst, das ist nämlich kurz bevor der Plot kommt. Kurz bevor das Gericht fertig ist. Wenn ich den Plot automatisiert bestimmen kann, dann kann ich den richtigen Zeitpunkt für die Werbeunterbrechung bestimmen. Wenn du als Zuschauer schon bis Sekunde 70 durchgehalten hast, weil dich wirklich interessiert wie der Kuchen aussieht, dann wird es jetzt viel einfacher sein, die Werbung auszuspielen, ohne dich zu verlieren gegenüber Sekunde 30, wenn du gerade erst in das Video eingestiegen bist. Das heißt, wir wollen in die Geschichte hineingehen. Wir wollen uns nicht das Produkt bzw. Video als Ganzes anschauen und sagen, dieses hat hunderttausend Klicks, und jenes nur fünfzigtausend Klicks. Sondern wir wollen mit Künstlicher Intelligenz in das Produkt hinein, in das Storytelling hinein und die Dramaturgie und den Spannungsbogen identifizieren. Damit unterscheiden wir uns bisher deutlich von allen anderen Startups und Firmen, die sich mit Video beschäftigen.
Gunnar Brune/AI.Hamburg: Sie wollen den Cliffhanger automatisiert identifizieren?
Ja. Das wäre noch viel besser, aber das ist noch ein sehr langer Weg. Doch wir sind auf dem Weg. Mit der Künstlichen Intelligenz haben wir die Tools jetzt alle in der Hand und es ist relativ einfach, die Technik zu nutzen. Man kann in der Cloud 100 Server hochfahren und binnen Stunden etwas berechnen, was früher Jahre gedauert hat. Dennoch haben wir noch einen langen Weg vor uns. In jedem Fall glaube ich, dass unser Ansatz, Filme zu optimieren ist richtig ist. So werden mit Künstlicher Intelligenz bessere Produkte entstehen und nicht nur Produkte besser verkauft werden.
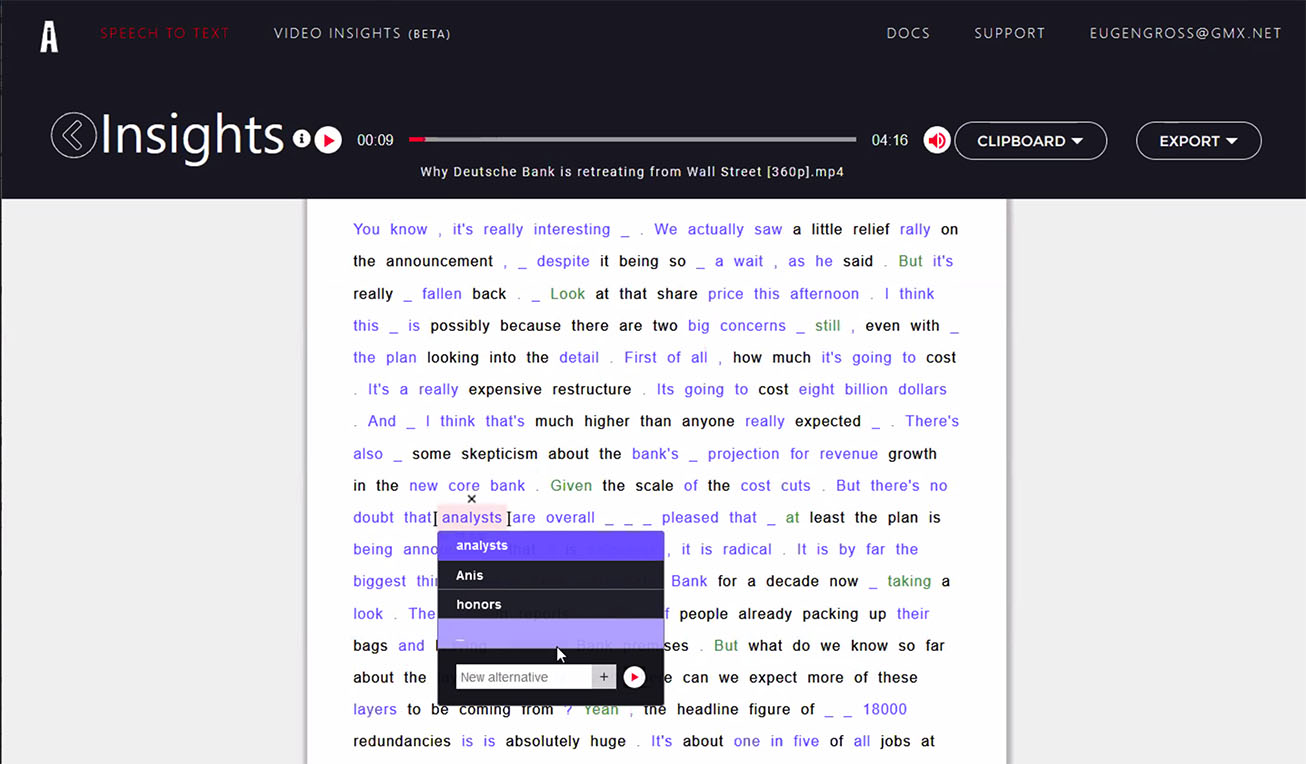
Blick in die Werkstatt der Künstlichen Intelligenz: Der aiconix-Algorithmus gibt eine Text-Empfehlung für die Ergebnisse verschiedener parallel laufender Speech-to-Text-Dienste.
Das Interview führt Gunnar Brune von AI.Hamburg

Gunnar Brune
Gunnar Brune ist Marketing Evangelist, Strategie-und Storytellingexperte. Er ist Unternehmensberater mit Tricolore Marketing, Gesellschafter des NEPTUN Crossmedia-Awards, Autor und mehrfaches Jurymitglied für Awards in den Bereichen Marketing, Kommunikation und Storytelling. Weiterhin ist Gunnar Brune im Enable2Grow Netzwerk assoziiert und engagiert sich im Rahmen von AI.Hamburg für die Vermittlung der Möglichkeiten und die Förderung des Einsatzes von Künstlicher Intelligenz.
Gunnar Brune ist Autor von dem Marketing Fachbuch „Frischer! Fruchtiger! Natürlicher!“ und dem Bildband „Roadside“. Er ist Co-Autor der Bücher: “DIE ZEIT erklärt die Wirtschaft” und “Virale Kommunikation” und er schreibt seit vielen Jahren regelmäßig für Fachmagazine. Seine Artikel finden sich u.a. in der Advertising Age (Fachmagazin Werbung USA), Horizont, Fischers Archiv und der RUNDSCHAU für den Lebensmittelhandel.
Kontaktinformation:
Gunnar Brune, gunnar@ai.hamburg, 0176 5756 7777


