

„Ganz oft bin ich fasziniert davon, dass die Komplexität nicht in dem einen Framework oder Algorithmus liegt, sondern darin, die verschiedenen Techniken so zu verknüpfen, dass genau das herauskommt, was für die Aufgabe benötigt wird.“
Dr. Robin P. G. Tech ist Geschäftsführer und Co-founder von delphai (https://www.delphai.com). delphai entwickelt Market Intelligence Software, die automatisch die neuesten Technologien und innovativen Unternehmen aus der ganzen Welt analysiert. Darüber hinaus ist Dr. Tech Forscher am WZB und MIT, Berater des Deutschen Bundestages über mehrere Ausschüsse hinweg, High-Tech-Koordinator beim Deutschen Startup Verband, Beirat von Blockchain for Science sowie Mitglied des Wirtschaftsbeirats von B90/ Die Grünen.
Gunnar Brune/AI.Hamburg: Wofür setzen Sie bei delphai künstliche Intelligenz ein?
Dr. Robin P. G. Tech: delphai ist eine Market-Intelligence-Software. Das bedeutet in unserem speziellen Fall, dass wir global Daten über Organisationen sammeln. Dazu setzen wir sogenannte Scraper- und Crawler-Programme ein. Das ist sehr ähnlich zu dem, wie Google seine Daten sammelt. D.h., diese Programme gehen “mit großen Netzen” durch das Internet und sammeln Daten. Google ist dabei natürlich an allem interessiert, wir “nur” an Organisationen. Wenn also einer unserer Crawler auf eine Event-Website geht, dann identifiziert er alle teilnehmenden Firmen, die die Konferenz besucht haben oder auf der Messe waren. Genauso machen wir dies mit Newslettern und mit Nachrichtenartikeln generell. Bis zu diesem Punkt werden dafür Suchroboter eingesetzt, die noch keine Künstliche Intelligenz nutzen.
Bei Nachrichtenartikeln kommt bei uns die erste Stufe unserer Künstlichen Intelligenz ins Spiel. Wir haben Algorithmen entwickelt, die automatisiert Texte dahingehend auslesen können, um welche Firma und um welches Thema es geht. Das kann z.B. ein neues Produkt, eine Akquise, eine Finanzierung oder ein anderes Thema sein. Aus der unstrukturierten Welt des Internet gewinnen wir so strukturierte Daten, die wir in Tabellenform ausweisen können. Ganz praktisch steht dann zum Beispiel in der ersten Zeile der Name des Unternehmens, in der zweiten Zeile der Standort des Headquarters usw. Mit diesen Ergebnissen fängt dann die nächste Stufe unserer Künstlichen Intelligenz an, die Organisationen und Unternehmen nach Industrien, Technologien und anderen Themen zu klassifizieren.
Gunnar Brune/AI.Hamburg: Welche Formen Künstlicher Intelligenz kommen bei dieser inhaltlichen Analyse von Texten zum Einsatz?
Dr. Robin P. G. Tech: Für jeden dieser Schritte setzen wir eigene spezifische Künstliche Intelligenz ein. Die Überführung von unstrukturierten in strukturierte Daten, die Klassifizierung von Unternehmen, das machen jeweils einzelne neuronale Netze, die genau dafür trainiert wurden, die können nichts anderes. Die meisten AIs, über die wir sprechen, sind „Narrow AIs“, die eine Sache richtig gut können. Meistens zumindest oder im Idealfall! Sobald man denen aber irgendeine andere Aufgabe gibt, dann sind sie komplett verloren. Für Textanalysen haben wir ein neuronales Netz, das speziell für die Identifikation von Produkten trainiert ist. Ein anderes neuronales Netz ist speziell auf Mergers & Acquisitions trainiert. Wenn man das eine auf den anderen Fall ansetzen würde, erhielte man keine sinnvolle Antwort.
Diese Arbeit erfolgt mit Künstlicher Intelligenz, die im supervised Learning trainiert wurde. Wir annotieren Daten, wir annotieren Text und bringen der AI bei, wonach sie Ausschau halten muss und soll. Den unsupervised Ansatz nutzen wir dort, wo Organisationen wenig Textdaten über ein Attribut produzieren. Man kann sich das gut vorstellen. Alle Organisationen haben Themen, über die sie viel und gerne sprechen. Firmen schreiben viel über Ihre Produkte und was sie alles toll machen. Aber, es gibt auch andere Themen, zu denen es vielleicht weniger zu erzählen gibt oder weniger kommuniziert werden soll. Trotzdem sind dies natürlich Attribute, welche die Firma hat. In diesen Fällen können wir dies nicht in den Texten annotieren und der AI zeigen, was wir suchen. Es gibt einfach zu wenig Material für supervised Learning, also muss die Künstliche Intelligenz selbst lernen. In solchen Fällen haben wir vielleicht Datensätze, dank derer wir von der Existenz eines Attributs wissen. Wir setzen dann verschiedene Modelle unsupervised ein und benchmarken die Ergebnisse mit dem, was wir schon wissen. Die Modelle, die dann untrainiert die richtigen Ergebnisse liefern, die behalten und verbessern wir. Das Gute an dem unsupervised Ansatz ist, dass wir der AI eben nicht sagen, wonach sie suchen soll, sie sucht die Auffälligkeiten selbst.
Gunnar Brune/AI.Hamburg: Sind diese AIs dann auch besonders wichtig für Ihr Unternehmen?
Dr. Robin P. G. Tech: Tatsächlich können wir anhand genau dieser AIs festmachen, wo wir einen Vorsprung haben. Ein schönes Beispiel ist der Bereich Natural Language Processing als Subkategorie von Künstlicher Intelligenz. Dieser hat in den letzten Jahren einen enormen Aufschwung gewonnen. Wir sehen dies an der Bedeutung, die Chatbots heute haben. Hier gibt es natürlich auch viel wissenschaftliche Aufmerksamkeit. Wir vergleichen unsere Ergebnisse mit denen der aktuellen Forschung, wie wir sie auf Preprint-Archiven wie „arXiv“ finden. Gerade bei dem unsupervised Ansatz in der Identifikation von Attributen von Unternehmen liegen wir in den Kriterien Accuracy, Recall etc. 6,5 Prozent über den Ergebnissen ganz neuer Preprints. Wir wissen daher, dass wir hier einen relevanten Vorsprung haben.
Gunnar Brune/AI.Hamburg: Sie liegen mit Ihrer Arbeit vor der Forschung? Liegt das auch daran, dass Sie in Ihrem spezifischen Feld über einen besonders umfangreichen Datensatz verfügen?
Dr. Robin P. G. Tech: Ja, das finde ich natürlich sehr cool und dafür lobe ich meine Mitarbeiter maximal. Denn auf der einen Seite stand in diesem Fall eine Gruppe von 10 WissenschaftlerInnen, die ein Jahr gearbeitet haben. Bei delphai dagegen sind wir insgesamt nur 30 Leute, und von uns haben nur 2 ½ an diesem spezifischen Set innerhalb von 2 Monaten bessere Ergebnisse produziert. Aber natürlich ist ein wichtiger Punkt, dass wir schon enorm viele Daten haben. Wir verfügen zu diesem Punkt über etwas mehr als 12 Millionen hochqualitative Firmendatensätze. Wenn man so einen Schatz hat, dann kann man ständig neue Fragen beantworten und so seinen Datensatz noch weiter ausbauen.
Gunnar Brune/AI.Hamburg: Sie haben beschrieben, dass Ihre Künstliche Intelligenz teilweise sehr spezifisch ist. Wie flexibel sind Sie dann?
Dr. Robin P. G. Tech: Die Infrastruktur dahinter haben wir so aufgebaut, dass wir sie immer wieder anpassen können. Das ist im Bereich von AI auch sehr relevant. Die Ergebnisse werden dann in Dashboards online dargestellt. Unsere Kunden nutzen Abo-Modelle und können mit der Software online alle Datenanalysen selbst durchführen.
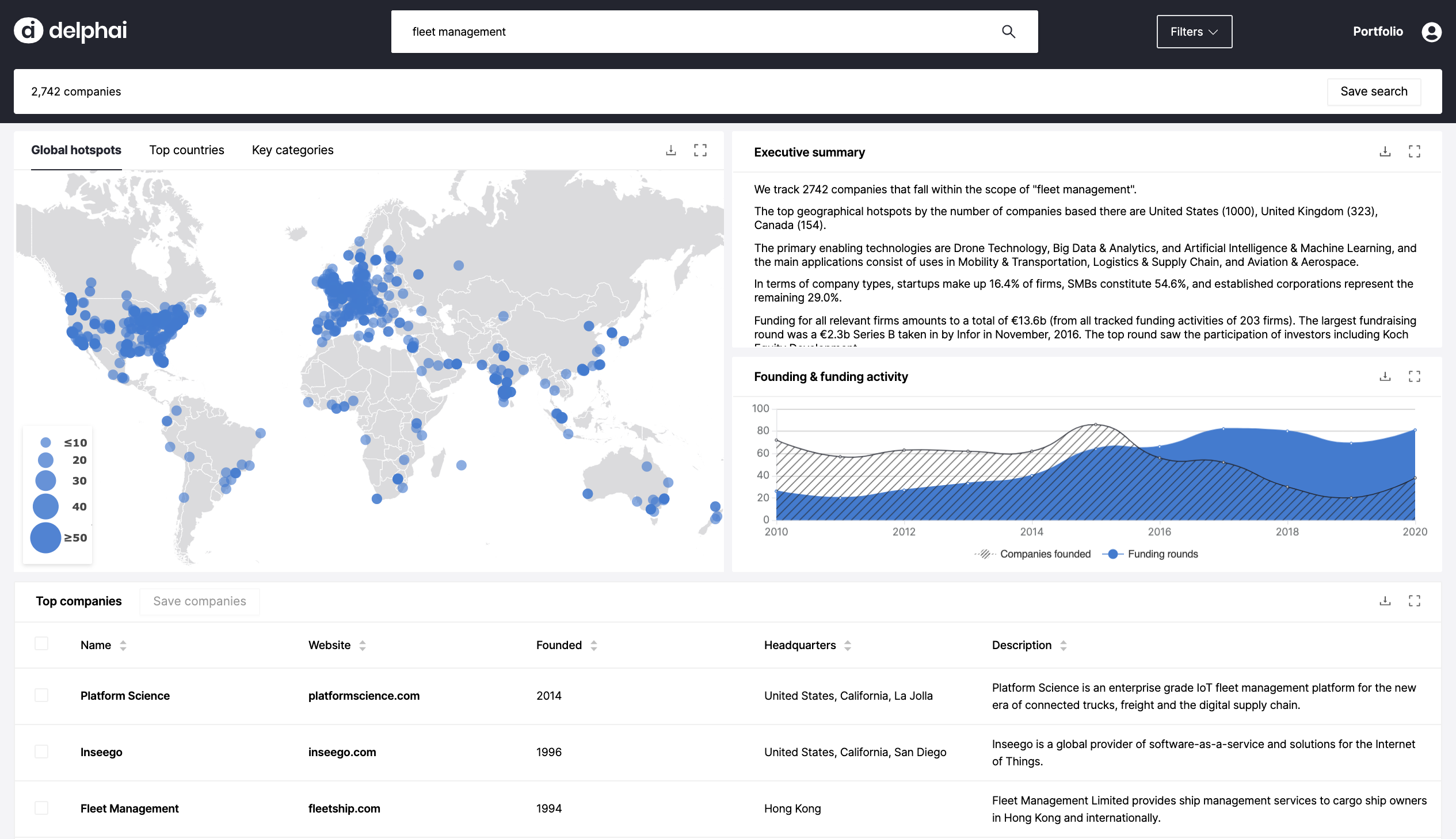
Auch in der Interaktion kommt Künstliche Intelligenz zur Anwendung, denn wir setzen Natural Language Queries ein. Ich kann dafür im Suchbalken Fragen eingeben wie: „Zeige mir alle Unternehmen für Fleet-Management-Software in Europa, die seit 2005 tätig sind“. Mit dem Drücken von „Enter“ wird die Maschine einen Datensatz generieren, der zu der Frage passt. Der Datensatz beinhaltet auch Graphen und Texte, so dass die Frage umfassend beantwortet wird.
Gunnar Brune/AI.Hamburg: Was machen Ihre Kunden mit diesen Daten?
Dr. Robin P. G. Tech: Die Kunden setzen unsere Services für unterschiedliche Themen ein. Sie betreiben Wettbewerbsanalysen, erstellen Kundenprofile, identifizieren Akquiseziele. Bisher waren dafür enorm zeitaufwändige manuelle Recherchen notwendig, denn man muss über Google, über Websites und andere Quellen suchen, um die jeweils aktuellen Informationen und News zu einem Unternehmen zu finden. In vielen Fällen sparen sie auch die Kosten für Teams von Unternehmensberatern, die bisher – und weiterhin – oft mit solchen Studien beauftragt werden.
Gunnar Brune/AI.Hamburg: Sie haben ein sehr differenziertes System aufgebaut, in dem Sie mit Künstlicher Intelligenz arbeiten: Einfache Suchalgorithmen, die noch nicht intelligent sind, spezifische, supervised trainierte Algorithmen und letztendlich die unsupervised trainierten und optimierten Modelle für besondere Fragen. Was sind das für Algorithmen, die Sie insgesamt nutzen und trainieren? Schreiben Sie diese selbst, oder sind es bewährte und bekannte Algorithmen?
Dr. Robin P. G. Tech: Ich bin überzeugt, dass jede Technologie-Entwicklung ein Remix von Dingen ist, die schon da sind. So gehen wir auch vor. Wir gehen nicht blind durch die Welt. Gerade in der Software-Entwicklung gibt es einen sehr regen Austausch zu Open Source Modellen. Anregung geben auch die Modelle BERT von Google oder BART von Facebook AI. Die Frameworks, in denen man arbeiten kann, sind auch definiert. Wenn man sich in die Facebook Welt mit PyTorch begibt, findet man ein ganzes Ecosystem von Menschen, die sich mit ähnlichen Fragestellungen auseinandersetzen, und darauf kann man natürlich ansetzen. Ich finde, das Coole ist, Stichwort „Standing on the Shoulders of Giants“, auf dem aufzubauen, was vielleicht nicht ein oder zwei Giants gemacht haben, sondern Tausende von anderen Menschen, die sich damit auseinandergesetzt haben. Es ist aber meist nur der erste Schritt, den man damit etwas schneller gehen kann. Danach kommen noch dreißig weitere, die wir selbst gehen müssen, um Anwendungen für unsere Anforderungen zu entwickeln und umzuformen. Ganz oft bin ich fasziniert davon, dass die Komplexität nicht in dem einen Framework oder Algorithmus liegt, sondern darin, die verschiedenen Techniken so zu verknüpfen, dass genau das herauskommt, was für die Aufgabe benötigt wird.
Diese Kombinationen von Techniken validieren oder bestärken sich auch immer wieder. Ein Beispiel: Wir haben einen Similarity Search Algorithmus, dessen Aufgabe es ist, Ähnlichkeiten zwischen dem Unternehmen A und den Unternehmen B und C zu identifizieren und am Ende zu sagen: Unternehmen B ist Unternehmen A ähnlicher als Unternehmen C. Das klingt zunächst relativ einfach. Aber dann haben wir festgestellt, dass die Klassifikationen für Industrien und Technologien, die wir darüber laufen lassen, ein zusätzlicher Impetus für den Similarity Search sein können. Und daraufhin haben wir auch noch gesehen, dass die Klassifizierung von den Quellen darüber hinaus auch noch mal ein Input sein kann. Wenn wir zwei Firmen immer wieder bei den gleichen Konferenzen sehen, ist das natürlich auch ein Aspekt von Ähnlichkeit. Das sind vielleicht super generelle Messen, wo alle sind, aber das können auch spezifische Messen sein, die ein weiteres Puzzleteil im Ähnlichkeitsalgorithmus abdecken können. Das meine ich mit der Kombination von Technologien und Input. Deshalb ist es manchmal ganz frech, wenn manche behaupten, sie haben den einen Algorithmus gefunden, der gleich alles erklärt.
Gunnar Brune/AI.Hamburg: Das würde mich genauer interessieren. Die traditionellen multivariaten Analysemethoden, wie zum Beispiel die Ähnlichkeitsanalysen, die in der BWL, im Marketing und in der Marktforschung eingesetzt werden, erfordern oft eine Reduktion der Genauigkeit, um eine Verständlichkeit für das Management und eine Operationalisierung zu erlauben. Sie gehen allerdings weiter und kombinieren Technologien bzw. Perspektiven, um präzisere Ergebnisse zu erhalten?
Dr. Robin P. G. Tech: So ähnlich. Die ersten Iterationen der Similarity Search liefen ausschließlich auf Website-Texten. Dazu wurde u.a. ein vektorisierendes Modell eingesetzt und der Algorithmus vergleicht diese Vektoren. Wenn also zwei Firmen ganz viel über IoT oder Industrieanwendungen geschrieben haben, dann hat sich aus den Websitetexten ein ähnlicher Vektor ergeben und das machte sie ähnlich. Was wir dann gemacht haben war, dass wir weitere Inputquellen hinzugezogen haben. Das waren die Ergebnisse der Scraper und Crawler. Es waren zunächst relativ simple Ergebnisse wie „Unternehmen A war auf der Hannover Messe“, „Unternehmen B war auf dem Mobile World Congress“. Andere Ergebnisse haben wir erst klassifiziert: D.h., aus einem Modell, in dem wir neuronale Netze eingesetzt haben, wurde ein Input generiert, der in ein weiteres Modell eingespeist wurde, nämlich in die eigentliche Similarity Search.
Gunnar Brune/AI.Hamburg: Für den Laien: Es ist eine Teamarbeit verschiedener Künstlicher Intelligenzen mit dem Menschen als Architekt und Trainer?
Dr. Robin P. G. Tech: Genau, und Teil davon ist nicht nur eine Vektorisierung, sondern auch ein supervised Ansatz. D.h., das neuronale Netz bekommt als Inputs zusätzlich die Vektorisierung und Klassifizierung und als Gold-Standard darüber hinaus die Trainings-Datensätze, die Menschen generiert haben. Und noch drei oder vier weitere Inputs.
Gunnar Brune/AI.Hamburg: Das war der Blick in den Maschinenraum, wie sieht das Ergebnis für den Kunden, den Menschen aus?
Dr. Robin P. G. Tech: Das ist bei delphai ein Online-, Self-Service-Dashboard, d.h. die Interaktionsebene ist eine Software, in der ich alle für Market Intelligence relevanten Fragen eintippen und Antworten genieren kann. Auf einer Makroebene werden Firmencluster dargestellt, zum Beispiel: Wo sitzen die Fleet-Management-Software-Unternehmen auf der Landkarte? Oder wo sind denn die Quantencomputer-Unternehmen? Dann wird dargestellt wie die Unternehmen zusammenhängen. Gibt es Cluster oder ist das super dispers? Gibt es vielleicht auch – wenn ich technologisch suche – prävalente Industrien, in denen eine Technologie heute schon häufiger eingesetzt wird? Oder gibt es “weak Signals“, weil es nur drei oder vier Organisationen gibt, die bereits in einer Nische aktiv sind. So kann man die großen Trends und die weak Signals identifizieren, die gerade erst als kleine Pflänzchen zu sehen sind.
Im nächsten Schritt hat man die Möglichkeit, sich mit einem sehr detailreichen und multidimensionalen Blick diese Firmen anzusehen. Was machen sie? Wie sind sie finanziert? Über die Similarity Search findet man auch die Konkurrenten. Man sieht die neuesten Produkt-News, Job-News, Patente, all das gesammelt dargestellt und in einer Ansicht nach Tabs geordnet. Hier kann man sich Listen von potentiellen Kunden, Wettbewerbern und Akquisezielen erstellen. Ab diesem Punkt vermag man die Listen auch kontinuierlich tracken. Zusätzlich haben wir ein Modul entwickelt, die eigenen firmeninternen Daten einzuspeisen, und die fließen dann als zusätzliche Information in die Suchen ein. Man kann also das eigene Unternehmen mit anderen Ecosystemen matchen. Und man kann Spezialisten suchen. Oder man kann die eigenen Business Units oder Kompetenzen mit den Clustern eines Ecosystems matchen.
Gunnar Brune/AI.Hamburg: Schauen wir noch weiter nach vorn. Künstliche Intelligenz funktioniert mit Daten und trainierten Robotern. Diese Roboter oder Maschinen, wenn ich sie einmal habe, kann ich relativ leicht multiplizieren. Das heißt, Sie sind in einem Geschäft, das sehr skalierbar ist.
Dr. Robin P. G. Tech: Das kann man so sagen.
Gunnar Brune/AI.Hamburg: Das hat die Gemeinheit, dass der „The Winner-takes-it-all“-Effekt sehr brutal sein kann. Wie gelingt es einer Firma wie Ihrer , gegen Unternehmen wie Google überhaupt zu bestehen?
Dr. Robin P. G. Tech: Das Beispiel Google ist gut. Da bestehen auch persönliche Verbindungen. Mein PhD-Stipendium kam von Google for Entrepreneurs. Wir haben von unseren Beiräten engen Austausch zu Google, SAP usw. Wir haben die natürlich auch gefragt, warum wir das eigentlich machen. Bei Google ist die Doktrin, dass unser Geschäft „Out-of-Core“ ist. Google will die allgemeine Suchmaschine sein. Sie hätten natürlich auch massive, monopolartige Marktvorteile, vielleicht ist das ein weiterer Grund. Vielleicht passt es auch nicht zur DNA des Unternehmens. Sei es, wie es ist: es gab irgendwann eine klare Entscheidung, unser Geschäft nicht zu machen.
Ich finde es selbst faszinierend, wenn ich Gespräche mit den CEOs von sehr großen Konzernen wie z.B. ABB führe. Man würde eigentlich denken, die sind gesetzt, die haben ihre Market-Intelligence Software und alles ist gut. Oder der große Automobilhersteller aus Norddeutschland, da denkt man, die sind so groß und so lange im Geschäft, die haben bestimmt die eine perfekte Lösung für Market Intelligence. Haben sie aber nicht. Das finde ich natürlich gut für uns.
Gunnar Brune/AI.Hamburg: Was meinen Sie, woran das liegen kann?
Dr. Robin P. G. Tech: Meine These ist, dass sich die Technologien zu schnell für diese Unternehmen weiterentwickeln. Nehmen wir zum Beispiel „Wer liefert was“, das ist ja quasi ein Monopolist in der Dachregion für Lieferantennetzwerke und -Kataloge. Die sind aber auch „stuck in the old days“ und in ihren Pfadabhängigkeiten, weil sie sehen, dass ihre manuell kuratierten Datenbanken mit einem altmodischen User-Interface seit Jahren gut funktionieren. Warum also sollte dies in Zukunft nicht weiter funktionieren? Und dann kommen andere und sagen: Nein, wir haben das alles automatisiert. Wir crawlen das Netz und wir können auf einmal automatisch herausfinden, wer eine Philips-Schraube in einer bestimmten Größe und Legierung liefert. Der eine Aspekt ist also der technologische Wandel, dem sich viele Incumbents nicht schnell genug stellen und sich nicht schnell genug weiterentwickeln. In anderen Worten, das ist das klassische Pfadabhängigkeitsproblem.
Der andere Aspekt ist, dass alle Nutzer einen jeweils anderen Blick auf den Markt haben. Nehmen wir das Beispiel der Similarity Search. Sie sagten, dass Sie dies aus der BWL kennen. Für Sie sind Unternehmen vielleicht ähnlich, welche in den gleichen Märkten tätig sind und ähnliche Umsatz- und Mitarbeiterzahlen haben. Ein anderer Kunde von uns kommt aber vielleicht aus der Forschung und Entwicklung. Für ihn ist ein ähnliches Unternehmen eins, das ähnliche Technologien einsetzt. Ob dieses Unternehmen in der gleichen Industrie arbeitet, ist in diesem Fall egal. Ob das eine Unternehmen 20 und das andere Unternehmen 20.000 Mitarbeiter hat, ist dann vielleicht auch egal. Hier ist vielleicht interessanter, ob beide Unternehmen Quantencomputer einsetzen.
Das bringt uns zurück zur der Diskussion über Künstlicher Intelligenz. Ganz viele der Entwicklungen sind sehr fokussiert. Man hat einen Algorithmus, und der kann eine Sache super, super gut. Damit wird eine Kundengruppe und deren Perspektive auf Market Intelligence abgedeckt. Aber wenn ein neuer Kunde mit einem anderen Blick auf die Märkte kommt, muss man im schlimmsten Fall von vorn anfangen. Wenn man Glück hat, so wie bei uns, entwickeln wir einfach ein weiteres neuronales Netz, das auf diese neue Anforderung trainiert ist. Es kann aber auch sein, dass der Kunde komplett neue Daten haben will und dann ist man komplett zurück auf Square one und muss erst mal neu beginnen, die Daten zu sammeln.
Das ist auch der Grund, warum Newcomer, wie wir im Bereich Marktbeobachtung, Marktanalyse, Marktstrategie immer wieder ein Chance haben werden.
Gunnar Brune/AI.Hamburg: Augenblicklich liefern Sie Ihren Kunden als Ergebnis der Arbeit der Künstlichen Intelligenz interaktive Dashboards, mit denen diese arbeiten können. Wohin geht die Reise, was dürfen wir in fünf Jahren erwarten?
Dr. Robin P. G. Tech: Ich kann nicht sagen, wie es in fünf Jahren aussehen wird, aber es gibt ein paar Pfade, die ich mir gut vorstellen kann. Einer davon ist auf jeden Fall der Datenpfad. Wir haben inzwischen eine Infrastruktur aufgebaut, mit der wir auch ganz andere Daten sammeln können. In Zukunft wird es nicht nur um Unternehmen, sondern auch um Forschungsprojekte gehen. Die werden genauso klassifiziert und nun kann ich Filter setzen für Unternehmen, Konzerne, Startups, Forschungsprojekte etc. Und es wird weitere Spielarten geben.
Was die Interaktion angeht, gibt es eine Entwicklung, dass Unternehmen sich ihre eigenen Dashboards bauen. Das finden wir auch total gut. Denn jedes Unternehmen, jede Abteilung hat eine eigene Perspektive auf die Welt. Es ergibt Sinn, die mit einem maßgeschneiderten Dashboard bzw. Interface darzustellen, welches vielleicht SAP oder die interne, eigene IT entwickelt hat. Das bedeutet, dass für delphai API-Calls gemacht werden. Wir definieren in diesem Fall gemeinsam mit den Kunden die Schnittstellen. Für unser Beispiel Similarity Search gibt es dann einen API-Call für similar Organisations und unsere Maschinen liefern als Output nur die Daten, aber nicht mehr das Interface.
Spannend ist auch, dass wir jetzt die Möglichkeit bieten, interne Unternehmensdaten mit einzuspeisen und dadurch der Maschine zu ermöglichen, Verknüpfungen zwischen bereits vorhandenen Kompetenzen und möglichen, neuen Geschäftsfeldern herzustellen. Ich glaube, dass da noch viel Potential drin steckt ist. Es disruptet auch den Ansatz von Unternehmensberatern wie McKinsey, denen man eine Million bezahlt, damit diese aufzeigen, wo man noch Neugeschäft machen könnte. Stattdessen gibt man der Maschine die Daten und sie schlägt schon solche Geschäftsfelder vor, die eine Verbindung zu den bestehenden Kompetenzen haben.
In Abstimmung mit zwei Stiftungen haben wir ein SDG-Classification-Tool entwickelt. Die SDGs sind die „Sustainable Development Goals“, 17 Ziele der nachhaltigen Entwicklung bis 2030, die von den Vereinten Nationen ausgegeben wurden. Hier haben wir es mit vielen „unbeobachtbaren“ Attributen zu tun, weil viele Firmen ihren Bezug zu den SDGs nicht kommunizieren oder vielleicht auch noch nicht analysiert haben. In wenigen Wochen können wir darstellen, mit welchen SDGs ein Unternehmen besonders große Anknüpfungspunkte hat.
Gunnar Brune/AI.Hamburg: Kurz mal nachgefragt: Das bedeutet, dass Sie in 2 Monaten ein Ranking der Dax-Unternehmen in Bezug auf die aktuelle SDG-Performance erstellen könnten?
Dr. Robin P. G. Tech: Fast, bzw. nicht ganz, denn dafür müssten wir eine Bewertung vornehmen. Aber wir könnten z.B. für den Standort Hamburg darstellen, wie sich die ansässigen Unternehmen auf die SDGs verteilen und welche SDG-Kompetenzcluster sich in Hamburg befinden.
Mit einer großen Rückversicherung arbeiten wir gerade an dem Thema Risk Assessment, also der Risiko-Klassifizierung von Unternehmen. Das waren die kurzfristigen Entwicklungen. Mittel- bis langfristig geht es bei uns darum, zu internationalisieren. Wir haben auch schon einen Kunden in den USA, und da geht natürlich auch noch mehr, denn unsere Daten sind global, also sind auch unsere Services global. Das werden wir als Nächstes angehen.
Gunnar Brune/AI.Hamburg: Danke für diesen Blick in die Zukunft. Sie sind Experte, für Sie sind diese Dinge sehr greifbar. Was sagen Sie denen, zum Beispiel im mittelständischen Unternehmen, die sich fragen, wie sie Künstliche Intelligenz einsetzen können, aber noch keinen Zugang finden?
Dr. Robin P. G. Tech: Das ist sehr idiosynkratrisch, denn es gibt Unternehmen, die schon viele Daten in weiterverarbeitbaren Formaten haben. Andere Unternehmen haben gar keinen Zugang dazu. Ganz grundsätzlich glaube ich, dass man sich der Technologie vom Output nähern sollte. Also nicht überlegen, welche Künstliche Intelligenz man nutzen will, sondern, was man erreichen will. Es gibt viele Beispiele, die Orientierung bieten können. Ein kleines Beispiel von einem großen Unternehmen sind die Weichen der Deutschen Bahn. Das Problem ist: Eine Weiche kann irgendwann kaputt gehen. Wie kann man das Problem angehen? Die Lösung ist, wenn wir die Stromabnahme der Weichen kontrollieren, dann können wir Anomalien der Stromabnahme identifizieren und dadurch vorhersagen, ob dieser Weiche ein Ausfall droht. Die Deutsche Bahn hat also nicht von vornherein gesagt, dass man unbedingt IoT, Sensoren und AI einsetzen will. Vielmehr hat man vom Problem ausgehend Lösungen gefunden, Technologien geprüft und Anbieter gebenchmarkt – von denen es ja auch schon viele für Predictive Maintenance gibt.
Die Kurzantwort ist also: Wie nähere ich mich Künstlicher Intelligenz? Fange mit einem Problem an, dass du hast und dann arbeite dich rückwärts zur AI vor.
Gunnar Brune/AI.Hamburg: Danke für dieses Gespräch.
Weitergehende Links zu Fachthemen in diesem Interview:
- Preprint Server arXiv: https://arxiv.org
- BERT (Google): https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
- BART (Facebook): https://arxiv.org/pdf/1910.13461.pdf
- Sustainable Development Goals: https://www.un.org/sustainabledevelopment/
- PyTorch: https://de.wikipedia.org/wiki/PyTorch
- Web scraping: https://en.wikipedia.org/wiki/Web_scraping
- Web crawler: https://en.wikipedia.org/wiki/Web_crawler
Das Interview führt Gunnar Brune von AI.Hamburg

Gunnar Brune
Gunnar Brune ist Marketing Evangelist, Strategie- und Storytellingexperte. Er ist Unternehmensberater mit Tricolore Marketing, Storyteller mit Narrative Impact, Gesellschafter des NEPTUN Crossmedia-Awards, Autor und mehrfaches Jurymitglied für Awards in den Bereichen Marketing, Kommunikation und Storytelling. Weiterhin ist Gunnar Brune im Enable2Grow Netzwerk assoziiert und engagiert sich im Rahmen von AI.Hamburg für die Vermittlung der Möglichkeiten und die Förderung des Einsatzes von Künstlicher Intelligenz.
Gunnar Brune ist Autor von dem Marketing Fachbuch „Frischer! Fruchtiger! Natürlicher!” und dem Bildband „Roadside”. Er ist Co-Autor der Bücher: “DIE ZEIT erklärt die Wirtschaft” und “Virale Kommunikation” und er schreibt seit vielen Jahren regelmäßig für Fachmagazine. Seine Artikel finden sich u.a. in der Advertising Age (Fachmagazin Werbung USA), Horizont, Fischers Archiv und der RUNDSCHAU für den Lebensmittelhandel.
Kontaktinformation:
Gunnar Brune, gunnar@ai.hamburg, 0176 5756 7777


